


Microsoft trained MAI-1-preview across roughly 15,000 NVIDIA H100 GPUs and rolled out MAI-Voice-1, a speech engine that can synthesize about 60 seconds of audio in under one second on a single GPU, a clear signal that Microsoft is pushing for lower cost-per-inference at production scale.
Microsoft has quietly shifted a major piece of its AI stack from reliance on external partners to models built inside its own labs. The debut pair (MAI-1-preview for text and MAI-Voice-1 for speech) are not incremental releases. They show a clear emphasis on running large-scale generative services more cheaply and faster, while keeping an eye on consumer-facing quality.
This launch is part tactical, part strategic. Tactically, Microsoft wants models that deliver faster responses and lower inference costs for features like Copilot and audio content. Strategically, owning core models gives the company more control over roadmap, integration, and how those models get updated over time. Microsoft has said it will still use partner and open-source models when appropriate, but this move reduces a single point of dependency in its stack.
Key takeaways
MAI-1-preview is Microsoft’s first in-house foundation text model made with a mixture-of-experts (MoE) approach and large-scale H100 training.
MAI-Voice-1 is an ultra-fast, expressive speech model already surfacing in Copilot features and labs; it targets production cost-efficiency for audio generation.
Microsoft frames this as greater autonomy while still using partner and open-source models where useful.
Key unknowns: exact parameter counts, dataset composition, pricing, legal/usage terms, regional rollout, and third-party benchmark comparisons beyond community leaderboards.
Actionable next steps: run cost-per-inference and latency experiments, test prompt tuning for your flows, evaluate voice quality on real scripts, and prepare governance checks (data lineage, safety filters, and compliance).
What MAI-1-Preview is and How It’s Built
MAI-1-preview is Microsoft’s first core language model trained end-to-end inside the company. Microsoft’s team reports a mixture-of-experts (MoE) architecture and very large-scale pre/post training across thousands of H100 GPUs, the sort of effort that signals production-grade throughput and a focus on efficiency. The MoE design lets the model route requests through specialized subnetworks, which can improve compute efficiency for many workloads compared with dense architectures.

From a product perspective, the headline features are practical: improved instruction-following for consumer tasks, faster inference at lower cost, and the potential for tighter integration with Microsoft’s cloud services and Copilot experiences. That means the model can be embedded in scrollbar-unfriendly contexts, chat, summarization, assisted writing, and knowledge retrieval, with the promise of lower latency and cost than some existing offerings.
What we do not yet have from Microsoft is a full technical model card. Critical details such as exact parameter counts, training corpus breakdowns, or fine-grained benchmark scores are not public. That will matter for teams that require transparency for compliance, research, or reproducibility.
MAI-Voice-1: a Lean, Expressive Speech Engine
MAI-Voice-1 is positioned more like an industrial TTS and speech generation system than a lab toy. Microsoft’s own demonstrations emphasize expressiveness (multi-speaker, conversational tones, storytelling) and speed: generating around a minute of audio in under a second on a single GPU. For any service that needs scalable spoken output, news digests, automated podcasts, narrated summaries, or voice-enabled assistants, that efficiency claim is meaningful because compute cost is often the largest line in running voice at scale.
Microsoft has already woven MAI-Voice-1 into Copilot Daily and Podcast-style features and made interactive demos available in Copilot Labs. That early placement is a pragmatic move: show the audio quality in real consumer contexts and iterate based on real usage signals. Developers and audio producers should test it for clarity, prosody, and how it preserves nuance in short-form and long-form uses.
Performance, Cost, and Infrastructure Implications of MAI-1-preview
Microsoft’s public remarks indicate a dual focus: high raw capability and lower operational cost. Two infrastructure signals are worth calling out:
Huge training scale: the reported use of roughly 15,000 H100 GPUs for MAI-1-preview training points to substantial investment in both compute and supporting data infrastructure. That level of scale typically shortens iteration cycles for model improvements and enables experimenting with larger or more complex architectures.
Inference efficiency for audio: MAI-Voice-1’s “<1s per 60s of audio on a single GPU” claim highlights where organizations with heavy audio workloads can see direct savings. For services producing hours of audio daily, a 10× or 100× improvement in throughput changes purchasing decisions and hosting architecture.
Operationally, this suggests three practical outcomes:
Lower cost-per-call when serving large volumes of text or audio.
Faster feedback loops for product experiments that require live or near-real-time responses.
Tighter integration opportunities with Microsoft cloud tooling (monitoring, scaling, and deployment) because the company controls both model and platform.
Yet, without published pricing and regional availability details, teams must run pilots or request early access to get real cost numbers for their use cases.
Where Microsoft is Placing these Models Today
Microsoft is not waiting to show value. Early placements include:
Copilot Daily and Podcast-style features, which surfaced MAI-Voice-1 to users as an audio-first experience.
Copilot Labs, where experiments let teams try expressive voice demos and audio manipulation in a sandboxed environment.
Public testing for MAI-1-preview via community leaderboards (for example, LMArena), where the model appears and is evaluated by independent community runs. Microsoft has also opened channels for early API testers.
This staged rollout strategy helps Microsoft gather usage data while testing operational limits in controlled consumer-facing surfaces. If your product roadmap depends on audio or chat features, those entry points are where you can start evaluation.
What Microsoft’s Move Signals Strategically
The broader signal is a shift toward self-reliance on key model technology while still keeping a multi-source approach. Microsoft’s public language is explicit: they will continue to use partner and open-source models alongside their own. Still, launching in-house foundation models reduces single-partner exposure and gives Microsoft more freedom over optimization, feature rollout, and pricing levers.
For competitors and ecosystem players, this changes negotiation dynamics. Companies that previously relied on external models and pricing frameworks can now expect another vendor with the ability to move quickly on both product features and wholesale price pressure. For cloud customers, it nudges a choice: adopt Microsoft’s integrated stack for ease and potentially lower cost, or remain multi-vendor to diversify risk and compare quality across providers.
Key Unknowns and What to Test First
Microsoft’s announcement leaves several practical questions unanswered. Before any large migration, teams should validate these items:
Actual pricing and billing terms. Trial numbers won’t predict steady-state costs unless you know per-token (or per-second audio) rates and volume discounts.
Data and training workloads. Without a model card, legal and compliance teams must ask about training data sources, filtering, and any provenance guarantees.
Regional availability and latency. Where the inference endpoints run affects compliance and user experience.
Benchmarks and fairness testing. Community leaderboards provide signals, but your use cases require your own evaluations for hallucination rates, bias across languages, and behavior on domain-specific queries.
Integration and SLA details. Uptime guarantees, latency percentiles, and throttling behavior can make or break real-time experiences.
Testing plan (quick checklist):
Run a cost-per-inference pilot on representative workloads.
Measure end-to-end latency inside your deployment region.
Conduct prompt-stability tests for core tasks (summaries, Q&A, code generation, etc.).
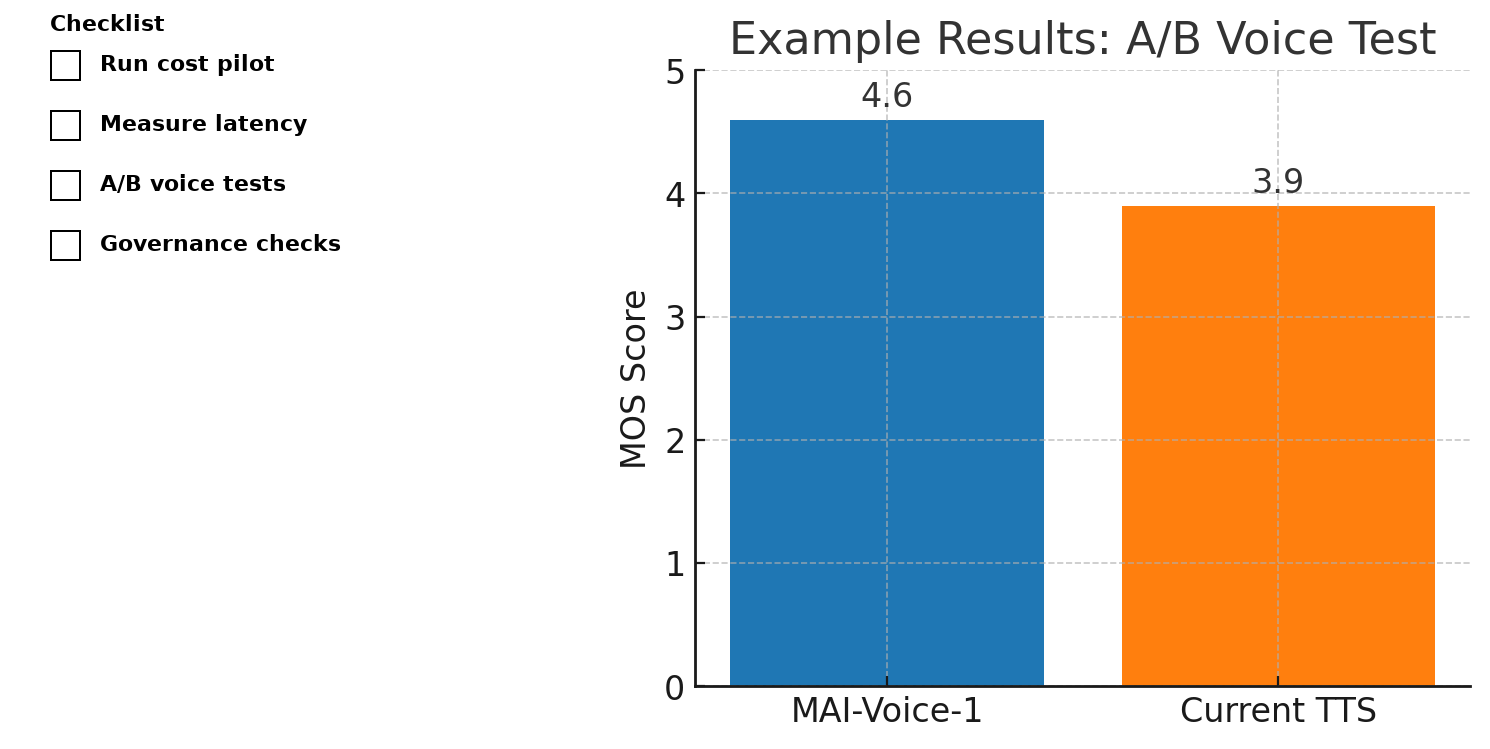
For MAI-Voice-1, run perceptual A/B tests against your current TTS system using real scripts and listener scoring.
Evaluate the model’s safety filters and content controls against your compliance baseline.
Practical Evaluation: a Short Lab Plan
If you have a two-week evaluation window, here’s a compact lab you can run:
Week 1: Baseline and connectivity
Day 1–2: Sign up for access, gather API keys, and run a smoke-test for text and audio endpoints.
Day 3–4: Implement a small wrapper that records latency and compute usage for standardized prompts and audio generation tasks.
Day 5: Run automated tests on 100 representative prompts; collect response quality, hallucination incidence, and token counts.
Week 2: Comparative and perceptual tests
Day 6–9: Run A/B perceptual tests for MAI-Voice-1 vs. your current TTS for short news reads and long-form narration. Use blind testers and simple MOS-style scoring.
Day 10–12: Load test to 10k requests/day to estimate peak scaling behavior and cost.
Day 13–14: Compile results into a migration recommendation with cost projections and risk notes.
Checklist for Product Teams
Use this list to align teams:
Run a cost pilot now. Estimate your per-session cost for text and audio flows for a 30-day window.
Measure latency and P99. Ensure real-time experiences stay within your UX targets.
Test content fidelity. For MAI-Voice-1, evaluate prosody, intonation, and emotional range with real scripts.
Validate safety filters. Run adversarial prompts and confirm acceptable guardrails.
Check legal and data lineage. Ask for any available documentation on training data and deletion policies.
Plan a staged rollout. Start with non-critical features (e.g., internal tools or beta users) before full production.
Keep parallel models. Maintain fallback paths to partner or open-source models during ramp-up.
These steps keep risk manageable while letting you capture the potential operational savings and user experience gains.
Governance, ethics, and compliance considerations
Owning the model does not remove governance responsibility. If your product handles regulated data, you must confirm:
Data handling: Are requests logged? How long are logs retained? Can users request deletion?
Safety and mitigation: What moderation layers exist? Is there a documented process for patching emergent failure modes?
Auditability: Can Microsoft provide a model card, training data summary, or redaction tools to satisfy legal reviews?
If you can’t get satisfactory answers, treat the model as experimental until documentation stabilizes.
Where to Try MAI-1-Preview and MAI-Voice-1
Microsoft seeded early access in places that show the models in context:
Copilot Daily and Podcast features: MAI-Voice-1 is already used for audio-first experiences.
Copilot Labs: experimental demos let teams play with expressive voice samples.
LMArena and community leaderboards: MAI-1-preview appears in public comparisons, giving an early sense of where it sits in open evaluations. Microsoft also offers an early API tester channel.
If you want to evaluate quickly, start with Copilot Labs to assess audio quality, then request API access for integration tests.
Conclusion
Rather than asking whether the new Microsoft models are simply “better” or “worse,” the more useful question is: how will faster, cheaper inference at scale change which features are viable? When audio costs drop and text inference gets quicker, teams can move from selective experiments to wide deployment: scalable audio content, on-demand narrated summaries, and embedded assistant features that react in real time.
Microsoft’s public framing captures the approach: they describe adding in-house models while continuing to use partner and open-source systems when beneficial. That is a pragmatic pathway, control where you need it, borrow where it’s better. As Microsoft AI put it, they’ll “use the very best models from our team, our partners, and the open-source community,” signaling a multi-source strategy rather than an exclusive pivot.
If you build with voice or chat, start a pilot this month. Compare cost, latency, and quality on the exact flows your users need. The trade-offs are now largely economic and operational; the differences in raw capability are narrowing fast.
References for Further Reading
Microsoft AI announcement and blog posts on MAI-1-preview and MAI-Voice-1.
The Verge coverage of MAI-Voice-1 placements and demos.
LMArena listing and community evaluation pages for MAI-1-preview.

Discover more from Aree Blog
Subscribe now to keep reading and get access to the full archive.











{kind=link}