
If you have ever embedded a tiny icon in a web page, opened a mail attachment, or inspected a JSON web token, you’ve run into Base64 encoding.
It’s a simple way to turn binary files into readable text so systems that expect characters, email gateways, APIs, browsers, can carry data without corruption. Because it’s everywhere and quiet, people sometimes treat it as more than it is. That’s the trap: Base64 is a format, not a defense.
In recent months the conversation around it has shifted from theory to practice, small, practical clarifications in the standards, concrete software advisories, and fresh examples of how attackers repurpose it. These changes don’t reinvent Base64, but they do change how teams should handle encoded data.
How Base64 Encoding Shows up in Real Systems
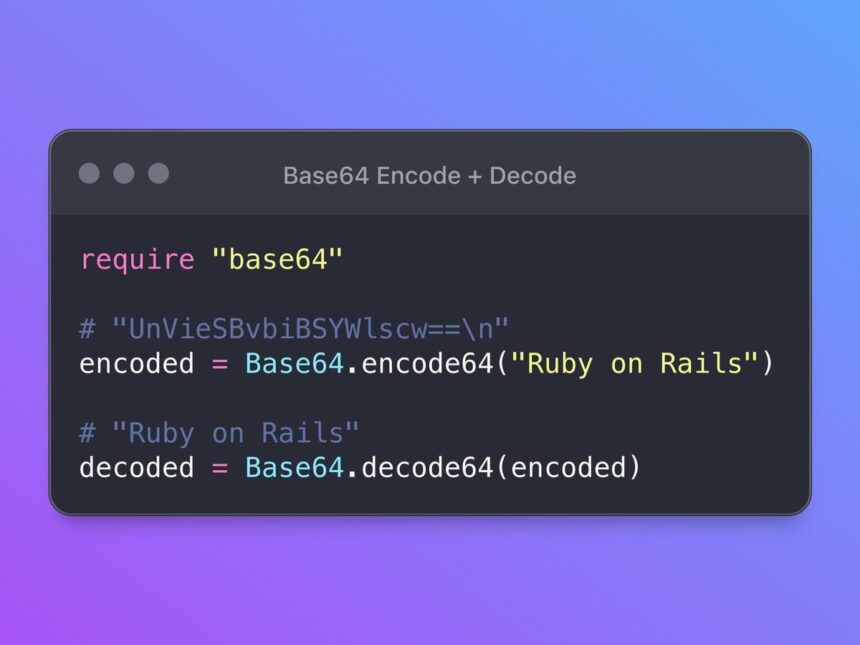
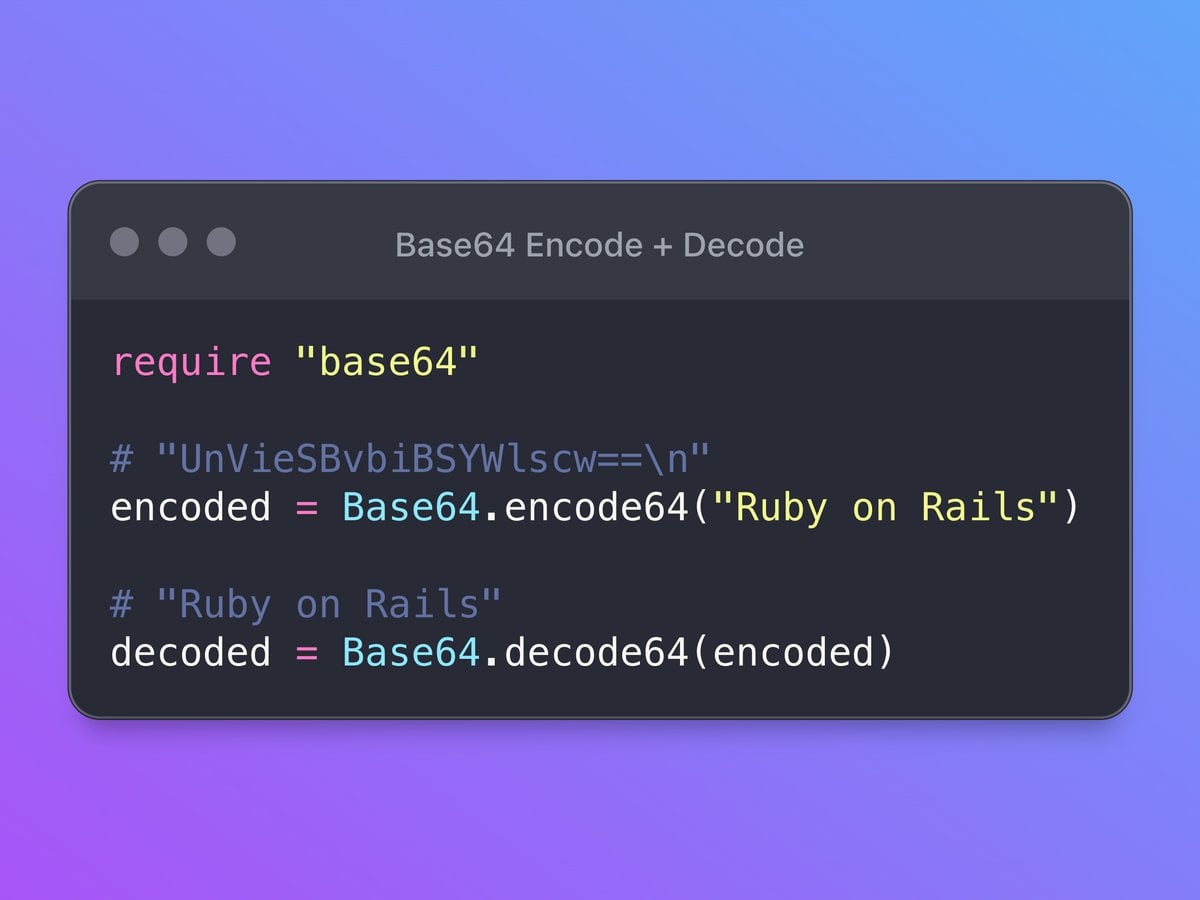
At heart, Base64 maps groups of 6 bits into one of 64 printable characters so binary files travel through text-only channels intact.
You see it used to embed images directly in HTML or to carry certificates and tokens across services. Because browsers and mail readers accept the text that results, Base64 is the plumbing that keeps many small but useful conveniences working.
That ubiquity is also why small differences between implementations can cause trouble. The IETF has been moving a revision of RFC 4648 toward an updated standard (the draft known as RFC4648bis) to clarify edge cases, padding rules, alternative alphabets, and how non-alphabet characters should be handled.
These clarifications aim to make encoded data behave the same way across languages and platforms, rather than introducing a radically different method.
What Changed in the Standards
The proposed RFC update doesn’t flip the table; it tightens a few bolts. The draft clarifies canonical encodings and handling of optional padding, which matters for interoperability when one library encodes slightly differently from another.
For developers, that means fewer surprises when an encoded payload created in one environment fails to decode in another.
If your systems exchange files across languages, watch for library updates and test round trips: encode in language A, decode in B, and verify the result byte for byte.
The standards update is a signal that vendors will likely tighten validation rules over time, so building idempotent tests now saves debugging later.
Security Conversations Around Base64 Encoding Today
Base64 itself does not provide confidentiality, but encoded strings routinely hide sensitive data inside logs and telemetry.
Detection tools that scan plain text can miss credentials or whole documents that are encoded and tucked away in application logs. Security teams have flagged this exact scenario in AI-centric logging platforms, where Base64-encoded entries have held tokens and documents that slipped past default filters.
That has triggered operational changes, better decode-and-inspect rules in log collectors and stricter redact/retention controls.
Beyond operational risk, there have been concrete software advisories. A CVE filed in January 2026 (CVE-2025-12781) highlighted that certain Python base64 decoding functions accepted characters outside the expected alternate alphabet when an alternate alphabet was requested.
In practice, that could lead to data integrity issues in applications that enforce a specific alphabet (for example, a URL-safe variant). The advisory and vendor notes recommend validating inputs and updating affected runtimes as fixes are released.
How Attackers Use Base64
Attackers have long used encoding as a simple obfuscation layer. A recent campaign analyzed by VirusTotal and covered broadly in industry reporting used SVG files containing Base64-encoded HTML and JavaScript to deliver phishing pages that evaded many signatures and antivirus engines.
The encoded content rendered in the victim’s browser and behaved like a mini web page; in one stream of incidents several dozen files initially bypassed detection. These incidents underline a clear pattern: encoding helps attackers glue malicious content to otherwise innocuous file formats.
Detection relies on decoding suspects and inspecting the result. That means expanding what logging pipelines and scanners consider “text” to include encoded payloads, and running those decoded strings through the same heuristics you apply to plain text, URL checks, link lookups, and static analysis.
Common Misconceptions and Safer Practices
A frequent error is treating Base64 as if it were a protective layer. If credentials or API keys are only Base64-encoded, they remain trivially reversible. Use a proper secret store or encryption when confidentiality is required.
Where Base64 is used purely for transport or formatting, confirm that the consuming system validates and sanitizes decoded content before processing or rendering it.
Operationally, adopt these practical steps:
- Have log collectors decode Base64 fields before retention or analysis so redaction rules apply equally to encoded content.
- When using URL-safe variants or alternate alphabets, add validation to reject unexpected characters rather than relying solely on library behavior. The recent Python advisory demonstrates why.
- Treat untrusted image formats like SVG as potential web content: disallow inline scripts where possible, and prefer image conversion to raster formats in high-risk ingestion paths. The SVG campaigns showed how vector formats can act like tiny web pages.
Steady Refinements, Not Revolution
Base64 encoding remains a simple, reliable tool for getting data from A to B. The current activity around it is not upheaval but a set of practical adjustments: clearer standards text to eliminate ambiguity, vendor advisories that prompt stricter validation, and renewed attention from defenders because attackers reuse encoding as a hiding layer.
Those are manageable developments, they reward the teams that treat encoded data as data to be inspected, not as something to be assumed safe.

Discover more from Aree Blog
Subscribe now to keep reading and get access to the full archive.












{kind=link}