


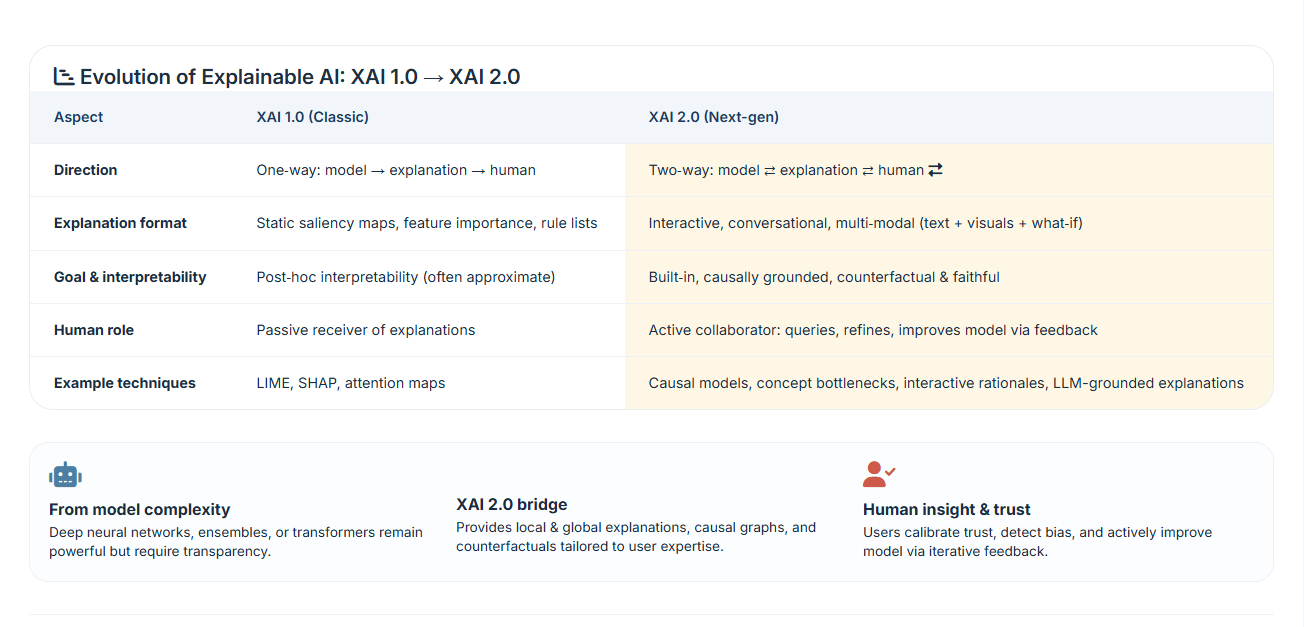
Over the last few years, explainable AI has quietly shifted direction. What started as a set of tools for interpreting predictions has turned into something closer to a reliability layer for machine learning systems. The term XAI 2.0 is now being used to describe this shift, particularly in how local explanations are designed, evaluated, and used in real environments.
Earlier approaches such as LIME and SHAP made it possible to answer a simple question: “what influenced this prediction?” That was useful, but it also exposed a deeper issue. In many cases, the explanation looked reasonable without actually reflecting how the model behaved. That gap has become harder to ignore as these systems move into production.
If you’ve ever run LIME multiple times on the same input and watched the explanation change, you’ve already seen the problem. It’s not theoretical. It shows up immediately once you try to rely on these tools for anything beyond demos.
Where Local Explanations Started to Break
LIME works by sampling data around a point and fitting a simple model locally. SHAP, on the other hand, distributes feature importance using Shapley values. Both approaches are well documented in their original papers (Ribeiro et al., 2016; Lundberg & Lee, 2017), and they’re still widely used.
But once you move beyond clean datasets, a few issues show up quickly. The explanations can be unstable, especially when the local sampling distribution shifts. Kernel width in LIME, for example, can quietly change the story the model tells. In practice, that means two analysts can look at the same prediction and walk away with slightly different interpretations.
There’s also the problem of plausibility. An explanation can look clean and intuitive while still being misleading. Several recent evaluation studies, including systematic reviews on explainability metrics, have pointed out that visual clarity often gets mistaken for correctness.
How XAI 2.0 Handles Locality Differently
One of the more interesting changes in recent work is how “local” is defined. Earlier methods assumed that distance in feature space was enough. That assumption doesn’t hold up well with complex models.
A newer approach, demonstrated in MASALA (2024), builds local regions based on how the model behaves rather than how the data is distributed. Instead of drawing a fixed-radius boundary, it identifies clusters where predictions follow similar patterns and explains within that space.
In simple terms, it stops asking “what’s close?” and starts asking “what behaves the same?”

That small change has a noticeable effect. Explanations become more stable, and more importantly, they stop shifting when you tweak parameters that shouldn’t have mattered in the first place.
Moving from Raw Features to Usable Concepts
Another limitation of early local explanations is that they operate on features that don’t mean much to humans. Highlighting individual pixels or token weights doesn’t always translate into something actionable.
This is where concept-based methods come in. Work like DSEG-LIME combines segmentation with pretrained models to produce explanations that map to recognizable patterns. Instead of saying “feature 42 contributed 0.18,” it can point to something like a suspicious phrase or a structural anomaly in a message.
If you’re building something like a scam detection system, that difference is huge. Users don’t care about feature indices. They care about whether the message shows signs of impersonation or urgency manipulation.
Combining Methods Instead of Choosing One
People are no longer treating explanation methods as mutually exclusive. In practice, combining them often produces better results.
For example, you might use SHAP to get a global sense of what the model pays attention to, LIME for a specific prediction, and a gradient-based method to visualize how a neural network is focusing internally. Studies like this multi-method evaluation in PLOS ONE show that these combinations can reduce blind spots that single methods miss.
This layered approach is starting to show up in production systems, especially where decisions need to be audited.
Counterfactual Explanations are Becoming the default
One pattern that keeps coming up in real deployments is the shift toward counterfactuals. Instead of listing contributing factors, the system explains how the outcome could change.
For instance, rather than saying a job message was flagged because of certain keywords, a counterfactual explanation might say that removing a mismatched company domain would change the classification. That’s easier to understand and easier to act on.
It also aligns better with how people naturally think about decisions. You’re not just asking “what happened,” but “what would need to change?”
What this Looks Like in Security Systems
This evolution is already visible in areas like intrusion detection. Earlier systems would flag anomalies without much context. With explainability layers added, analysts can now see which patterns triggered the alert and how those patterns evolved over time.
There’s a practical example in recent work on explainable intrusion detection models, where LIME and SHAP are used to break down predictions from neural networks. The results are not perfect, but they’re enough to make the system usable for investigation rather than just detection.
The same idea applies to scam detection. Instead of flagging a message as risky based on isolated signals, newer systems identify patterns like identity inconsistency or coordinated phrasing. The explanation becomes part of the product, not just a debugging tool.
Where the Gaps Still Are
Even with these improvements, there’s still no agreement on how to measure explanation quality. Different metrics capture different aspects, and they don’t always align.
There’s also a new concern around adversarial behavior. If explanations become part of the interface, they can potentially be manipulated. That’s especially relevant in security contexts, where attackers adapt quickly.
Regulatory pressure is also shaping development. The EU AI Act, for example, introduces requirements around transparency that push organizations to go beyond surface-level explanations.
What’s clear is that local interpretability is no longer just a research topic. It’s becoming a practical requirement for systems that need to be trusted, audited, or understood by people who didn’t build them.

Discover more from Aree Blog
Subscribe now to keep reading and get access to the full archive.











{kind=link}